
Seeing Through Their Eyes
Categorizing Individuals by Their Gaze Patterns in 3D Scenes
Eye Tracking, Scan Path, Virtual Reality, Gaze Representation, Deep Learning
Note: This project reflects on my previous research [ Deep Spatial Memory ] in spatial perception, shifting the focus toward individual differences. Instead of analyzing spatial experience as a universal phenomenon, it explores how personal factors shape the way individuals perceive architectural environments.
💡
How can we identify and categorize individuals based on their unique gaze patterns while viewing immersive 3D environments? How can we learn their distinct viewing strategies or attention profiles?
Introduction
This project explores how eye-tracking data can be used to identify and categorize individuals based on their unique gaze patterns while viewing immersive 3D environments. Traditional gaze analysis methods rely on coordinate-based representations, which often lack semantic meaning. This project investigates alternative multi-modal representation methods, leveraging machine learning to group individuals based on their viewing behaviors without requiring explicit labels. By analyzing gaze scanpaths in a structured manner, this study aims to uncover patterns in attention and perception across different user groups.
Methods
Data Collection: The study used Meta Quest Pro with a custom C# script in Unity to record eye-tracking data while participants viewed a 7-minute 360-degree video featuring 16 distinct urban and architectural scenes in Jerusalem. A total of 11 participants participated in the study.
Data Processing: Eye-tracking data was processed using established methods for fixation and saccade detection:
Fixations – Identified using I-DT (Dispersion Threshold Identification), where gaze points within a 1° dispersion over a minimum of 50 ms were labeled as fixations.
Saccades – Detected using IN-VT (Velocity Threshold Identification), identifying rapid gaze shifts exceeding 70°/s with a duration between 17 ms – 200 ms.
The raw eye-tracking data was processed by filtering out saccades and retaining only fixation points, as fixations indicate where participants focused their attention. For each fixation, a viewport—a square patch of the visual content centered around the fixation point—was extracted, capturing the local visual context of what the participant was observing.
Gaze Representation: The final gaze data format include 2 arrays: a Fixation Coordinate Array, storing (x, y, z) positions of each fixation in 3D space, and a Fixation Image Array, containing cropped visual patches corresponding to each fixation. To standardize sequence length while preserving natural gaze flow, an adaptive sampling approach was applied
Representation Learning: A self-supervised framework using Transformer is applied to learn discriminative gaze representations without requiring explicit labels. The contrastive loss is applied to the [CLS] token of each sequence.
Clustering: The learned [CLS] token representation of each gaze sequences are used to group participants using unsupervised K-Means clustering algorithm.
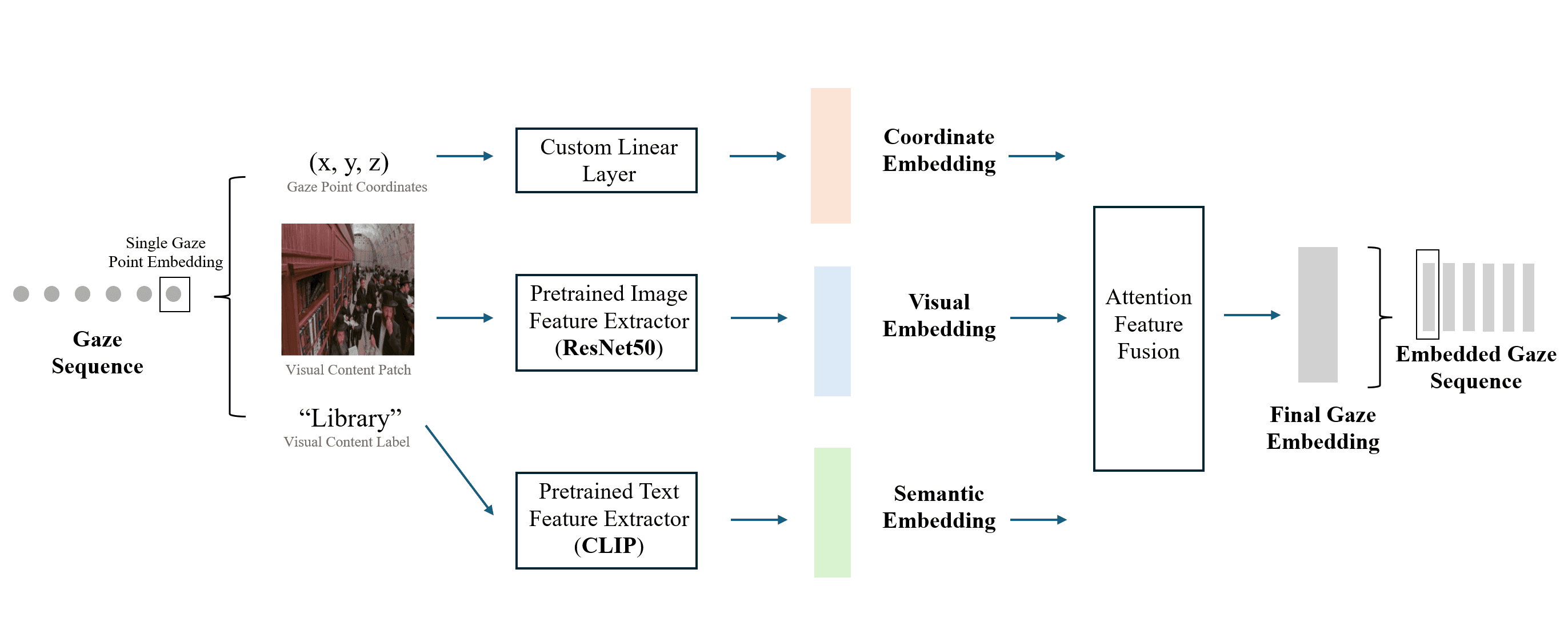
Process of Embedding Gaze Sequence
Self-Supervised Contrastive Representation Learning
To move beyond traditional coordinate-based gaze representations, the study introduced deep learning-based semantic embedding using Transformer framework:
Coordinate Embedding: A custom linear layer project the (x,y,z) coordinates of gaze points to an embedding space.
Visual Feature Extraction: A pretrained ResNet50 model was used to extract semantic features from image regions corresponding to gaze fixation points.
Textual Context Encoding: A CLIP-based model was applied to integrate semantic meaning from textual descriptions of objects within the gaze field.
Multi-Modal Feature Fusion: A custom linear transformation layer combined coordinate-based embeddings with visual and semantic embeddings, creating a rich gaze representation that incorporated both spatial and contextual meaning.
Self-Supervised Transformer Encoding: A Transformer encoder processes gaze sequences, where each gaze point is embedded and fed into the model as a token. The [CLS] token is trained to learn a compact summary of the entire scanpath.
Similarity-Based Representation Learning: Gaze scanpaths were transformed through augmentation techniques (e.g., playback speed adjustment, translation shifts) to learn invariant representations of gaze behavior. Contrastive loss is applied to the [CLS] token representation of each sequence by pulling together similar (augmented) gaze sequences and pushing apart dissimilar ones.

Similarity-based Representation Learning
Experiments
The experiment took place in a controlled indoor setting. The VR headset used was the Meta Quest Pro, which features integrated eye-tracking capabilities and default eye-tracking calibration. A custom C# script in Unity was developed to facilitate data recording, and synchronization with video playback. The experiment involved 11 participants (7 female, 4 male), recruited from various academic backgrounds: 7 Architecture, 2 Art, 1 Material Science and 1 Philosophy. Each participant underwent below steps:
Eye-Tracking Calibration: Before data collection, participants completed an eye-tracking calibration process built into the Meta Quest Pro system. The calibration required them to focus on moving target points displayed within the VR headset to optimize gaze accuracy. Participants are asked to evaluate the calibrated eye-tracking performance before proceeding.
Instruction: Participants were introduced to the purpose of the study and provided with basic instructions. They were asked to freely observe the upcoming 360-degree video and pay attention to elements that caught their interest. They were not given specific tasks (e.g., looking for objects) to ensure that gaze behavior remained natural and unbiased.
360-Degree Video Viewing: The participants then watched a 7-minute 360-degree video featuring 16 different scenes of urban and architectural spaces in Jerusalem (e.g., churches, plazas, rooftops, gates, libraries, and streets). The video was played within a custom standalone VR application that triggered real-time gaze data collection upon playback.Each scene lasted approximately 20 seconds, allowing enough time for participants to explore visual details naturally.
Post-experiment Questionnaire: After completing the video viewing, participants filled out a questionnaire to provide: Demographic information (gender, age, academic background), VR experience (prior exposure to VR environments), most visually striking elements or scenes, whether they experienced any dizziness or discomfort.

Left: 16 Architecture Scenes in the Online 360 Video. Right Above: Built-in calibration process before watching video. Right Bottom: The subject wearing VR headset is watching the 360 video
Results
To evaluate whether the collected eye-tracking data exhibited inherent differentiation, an initial data visualization was performed. The scan paths of participants from architecture and non-architecture backgrounds were compared across various scenes to observe patterns in visual saliency. In certain scenes, clear distinctions emerged; for instance, in the church scene, architecture students tended to focus on high architectural elements such as vaults, stained glass windows, and structural details, whereas non-architecture students were more drawn to human-related elements like priests, religious paintings, and musical instruments. However, in stimulus-rich environments like narrow streets filled with merchants and storefronts, both groups exhibited similar gaze behaviors

Comparison of Averaged Visual Saliency between Two Groups Students: Upper row is architecture-background students. Bottom row is non-architecture bacground students. In left two columns, they express distinct viewing patterns. However for the right two columns, due to complex human-related stimulis, they bahave similarly.
These observations highlight the limitations of using academic background as a single categorical label to explain gaze pattern similarities and differences, as gaze behavior is likely influenced by multiple factors beyond major alone. To overcome this, a self-supervised learning approach was applied to learn data-driven representations of gaze sequences, allowing the model to discover latent structures in gaze behavior without predefined labels. The self-learned features were then analyzed using a K-means clustering algorithm, revealing how the machine differentiates gaze patterns based on inherent similarities rather than relying on manually assigned categories.

Clustering of Self-Learned Features on Library Scene
Future Steps
This study demonstrates that self-supervised learning can effectively capture gaze behavior patterns, revealing latent structures in visual attention that go beyond predefined labels like academic background. Potential future steps include:
Improving Data Quality – The use of online 360-degree videos introduces uncontrolled variables, such as human movement and unpredictable stimuli. Future studies should use self-recorded 360-degree videos to control environmental factors, ensuring more reliable comparisons.
Evaluating Machine-Learned Clusters – Further research is needed to assess how well self-learned gaze clusters align with real-world viewing behaviors, potentially through user studies or expert evaluations.
Exploring Collaborative Filtering – Inspired by recommendation systems, collaborative filtering algorithms could be investigated to extend gaze similarity clustering toward personalized applications, such as adaptive visual guidance in VR environments or customized content recommendations based on gaze behavior.